
こんにちはー。リバーシプログラムが絶賛マイブーム中のかけるです。
はじめに、Alpha-Beta法とは何ぞやという方は、こちらの記事「【リバーシプログラム】強いAIを目指すための探索アルゴリズム」をご覧くださいな。
今回は、そんなAlpha-Beta法の枝刈りに関する妙案をひとつ。
はじめに
Alpha-Beta法の解説自体は、本ブログに限らずとも少し探せばいくらでも見つかると思います。――が、前記事も含め、解説されているAlpha-Beta法の多くはN手目の評価値がN-1手目の評価値以下(以上)であることを枝刈りの条件としているケースがほとんどです。
そこで今回、本ページで紹介する妙案とは「もっと大胆に枝刈りできるんじゃね?」という発想で試してみたものです。
Alpha-Beta法の枝刈り改善案
下図は5手読みのAlpha-Beta法による探索改善案を示した図です。
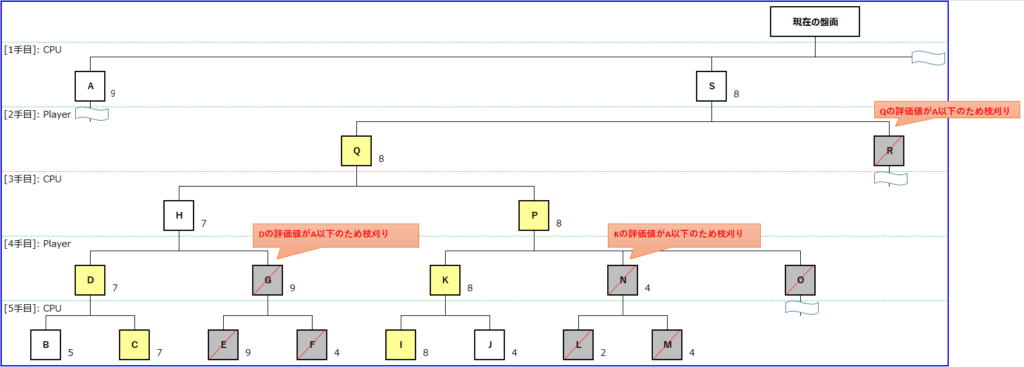
前記事で紹介した手順でもって探索を進めるのであれば、Gの評価値を決めるためには少なくともEの盤面を探索する必要があります。
Dの評価値は7です。この状態でEの評価値が8以上であったなら枝刈りが発生してFの探索はスキップされ、Dの評価値がHの評価値と決まります(CPUから見て対戦相手であるPlayerは、CPUにとって悪い手を選ぶと考えられるため)。
――では、逆にEの評価値が7以下だった場合ですが、この場合は枝刈りは発生せずにFの探索が行われます。
ここまでは前記事のお話です。今回、ここで注目したいのがAの評価値です。
おさらいになりますが、B~Rを探索する理由はSの評価値を調べるためです。つまり、Dの評価値もSの評価値になり得る値のひとつということです。
少し極端に思えるかもしれないが、Eの評価値がAの評価値を下回っていた場合、たとえDの評価値を上回っていたとしても最終的にSの評価値として決まった場合にSの手が選ばれない(評価値の高い手を選ぶため)ことが確定します。
Eの評価値がAの評価値を上回っていた場合は、先述したとおり枝刈りが発生する。
したがって、Eの評価値が8以上の場合はDの評価値が選ばれ、Aの評価値を下回っていた場合はその値がSの評価値となったとしてもSの手が選ばれないことが決まるため、E~Gの探索が不要と判断できます。また、同じ理由でN以降、R以降のノードについても枝刈りして問題ないといえます。
改善効果
今回も参考がてらに改善効果のほどを以下に示します。
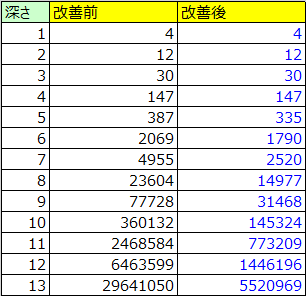
上記はそれぞれAIが先攻1手目で探索した場合の局面数を表しています。
枝刈りの範囲を増やしたことにより、探索した局面数が大きく削減できていることがわかります。それでも60手すべてを読み切ることは敵いませんが……。
もちろん、枝刈りは選ばれないと確定した手でのみ行われるため、探索で得られる結果は前記事で紹介したMini-Max法/Alpha-Beta法による探索と同一になります。
おわりに
Alpha-Beta法をより発展させた探索手法としてNega-Scout法やMTD-fといったものがありますが、それらの土台になっているのはAlpha-Beta法なので、この妙案も何かしら意味はあるはず(と思いたい)。
また、Alpha-Beta法で行われる枝刈りはその仕組み上、最初のうちに有効な手を探索できればその分だけ枝刈りできる量を増やすことができます。この探索順序を操作する考え方としてムーブオーダリングと呼ばれる手法がありますが、それはまた時間があるときに……。
以上、最後まで読んでいただきありがとうございます!それでは、また(・ω・)ノシ


コメント